Mysql-cluster数据库集群双机HA研究

一、双机Mysql-Cluster存在的问题
对于一个Mysql-Cluster,有管理节点、数据节点和访问节点,基于官方的部署至少需要三台服务器分别充当这三种角色。然而在实际部署中可能只有两台服务器,那么怎样分配这两台服务器的角色,使其具备HA(High Aviable)特性呢?两台服务器分别用node1和node2来代替。对于角色的分配,大致有两种类型:
- node1、node2只充当部分角色
- node1、node2都同时充当管理、数据和访问节点
对于第一种情况,任意一台服务器出现故障(进程被杀、断电关机、网络不通等)的话,另外一台服务器可能就不能对外正常提供服务,也就是常说的单点失效故障。对于第二种情况,任意一台服务器出现故障的话另外一台仍可以对外正常提供服务,可以避免单点失效,但是会引来脑裂故障。

设想,node2的网络不通了,此时node1和node2之间不能通信了,则会互相认为对方出现故障了而去接管集群,当node1和node2之间通信恢复的时候,集群则会不知所措了,因为都会认为自己的数据是最新的而让另一节点进行数据同步,这样mysql-cluster会在重启几次之后而关掉,即使手动去启动集群也无法启来的。
二、问题重现
经以上分析Mysql-Cluster双机集群会出现单点失效和脑裂故障。因为在第二种情况下可以避免单点故障,但是引来了脑裂的问题,所以本文采用第二种方案来研究双机HA的实现。
1. 测试环境
Debian:debian-6.0.7-i386-CD-1.iso
MySql:mysql-cluster-gpl-7.2.7-linux2.6-i686.tar.gz
- Node1:192.168.236.138
- Node2:192.168.236.139
- GateWay:192.168.236.2
配置文件见这里
2. 故障及分析
2.1 进程无故关闭(提到的down掉就是进程死掉)
1)Ndbd进程
- node1和node2的任意一ndbd进程down掉,集群仍可对外正常提供服务,节点的ndbd 进程down后,再次启动亦可自动加入集群。
- node1 先down掉,在node1没有启动ndbd时node2接着down掉,然后以任意顺序启动ndbd进程或只启动其中一个节点的ndbd,集群即可对外正常提供服务。
- node1和node2同时down掉,集群不可对外提供服务,但当节点以任意顺序启动ndbd进程或只启动其中一个节点的ndbd,集群即可对外正常提供服务。
2)Ndb_mgmd进程
- node1和node2的任意一ndb_mgmd进程down掉,集群仍可对外正常提供服务,节点的ndb_mgmd进程down后,再次启动亦可自动加入集群。
- node1和node2的ndb_mgmd同时down掉,集群可以正常对外提供服务,然后以任意顺序启动ndb_mgmd进程或只启动其中一个节点的ndb_mgmd,集群亦可对外正常提供服务。
3)Mysqld进程
由于设置了mysqld的ArbitrationRank,则mysqld也参与了决策,但是其决策级别低于ndb_mgmd。因此在两个ndb_mgmd都down掉的时候集群仍可以正常对外提供服务。因次只考虑当两个ndb_mgmd都down掉的情形。
- 任一个mysqld进程down掉,则另外一个mysqld节点仍可对外提供服务。当另一个mysqld进程down的节点重新启动mysqld进程,但此时该节点仍不可对外提供服务,此时若任意一个节点的ndb_mgmd进程启动,则两个节点都可正常对外提供服务.
- 任一mysqld进程down掉,对外提供一段时间的服务后,另外一个mysqld进程也down掉,则集群不可对外提供服务,此时需开启ndb_mgmd集群才能对外提供服务。
- node1和node2的mysqld同时down掉,集群不可对外提供服务。
2.2 网络故障(提到的失效就是网络不通)
在Node1和Node2的管理节点、数据节点、访问节点都正常的情况下,其中的一个节点网络出现故障,导致node1和node2不能通信,但另外一节点仍能和外界通信提供数据服务,此时会出现脑裂现象。
根据失效节点的不同可以分为:
- master节点失效,则备份节点会自动重启成为master节点(需要一会时间),继续对外提供服务。
- 备份节点节点失效,则master节点可不间断对外提供服务。
三、解决方案
双机集群不管怎样设置配置文件,都不可避免的出现脑裂现象。经过分析,可以用以下方案来解决脑裂造成的数据不一致现象。每个节点都有一个daemon进程,该进程会不间断的检测网络状况:
- ping 网关
- ping 另外一个节点。
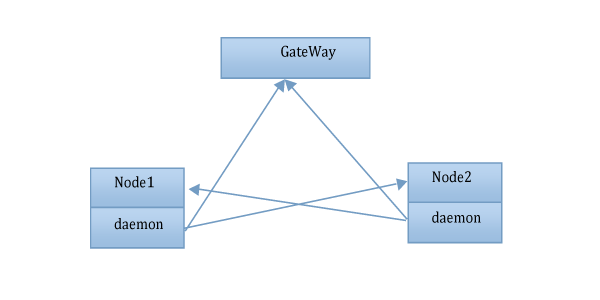
ping不通网关,则此时也必ping不通另外一个节点,此时daemon进程即可做出决策是自己的网络有问题了,然后自己将本节点的集群关闭。daemon仍不间断的去检测网络是否畅通,若可以ping通网关则证明自己网络好了,此时:
- 若ping的通另外的节点,则证明另外一个节点是正常的,然后daemon进程启动本节点的集群;
- 若ping不通另外节点则说明另外一节点也出现故障了。
在第2种情况下,可能会是一个节点网络故障了,另外一个节点对外提供一段时间的服务后网络也出现故障造成的,这时节点间的数据是不一致的,很明显后失效的节点的数据是最新的。这时后失效的节点的集群是不能关闭的,当网络畅通以后,最先失效的节点也会加进来,两个节点间的数据仍可以同步为最新的。最不幸的事也是会发生的,一个节点失效了一段时间后另外一个也失效了,不仅失效而且断电或管理员不小心halt了系统。这时node1和node2 的集群的启动顺序就很重要了,不留神的话旧数据会覆盖新数据的。因此我们的daemon进程要有决策哪个节点的数据是最新的能力并且先将它启动。
四、总结
经分析,在ndbd、ndb_mgmd和mysqld节点不同程度的down掉,对集群的影响不是很严重,但是脑裂情况不可避免,但是我们可以通过写辅助程序来补救,使Mysql-Cluster双机集群实现HA。
本研究方案中mysql集群的安装、配置和daemon程序见这里